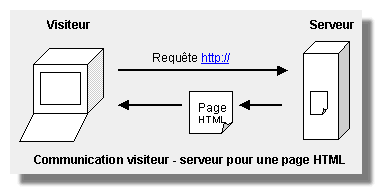
 Dans le cas d'une page HTML classique, l'échange est très simple. Le visiteur envoie une requête au serveur : l'url de la barre d'adresse, soit par exemple http://www.toutjavascript.com/index.html. Le serveur lit le fichier index.html stocké sur son disque dur et l'envoie directement et tel quel au visiteur. Le navigateur reçoit alors le fichier HTML, interprète le code HTML et javascript qu'il contient et l'affiche à l'écran. |
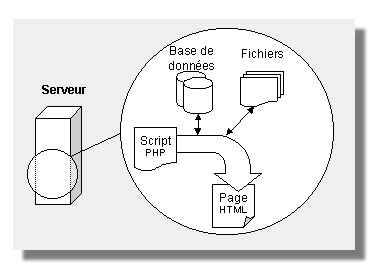 Dans le cas d'une page PHP ou ASP, le serveur a un rôle plus actif et ne fait pas simplement office de facteur. Le visiteur envoie toujours et de la même manière une requête au serveur, par exemple http://www.toutjavascript.com/main/index.php3. Le serveur ouvre le fichier index.php3 du répertoire main. Ici l'extension de la page est différente pour montrer au serveur qu'il a une action supplémentaire à faire. Le fichier index.php3 est un script, c'est-à-dire une succession d'instructions, que le serveur exécute. Le résultat de ce script est un fichier contenant du code HTML et javascript qui est ensuite renvoyé au navigateur du visiteur. Ici, il y a une étape supplémentaire, un ensemble de traitements exécutés par le serveur, entre la requête et l'envoi de la page. Ces traitements peuvent être de tous types, mais le plus souvent, le serveur lit une base de données pour en extraire les dernières news du site ou les résultats actuels du sondage. Il peut aussi compter le nombre de visiteurs connectés au site et l'afficher sur la page. C'est le cas pour la page d'accueil de ce site. Ces traitements font travailler le serveur et consomme de la mémoire et du temps processeur. C'est pour cette raison que les hébergeurs gratuits ne proposent que seulement depuis quelques temps des langages serveur, le plus souvent PHP, à la fois pour être compétitifs et grâce à l'augmentation de la puissance des machines serveurs. |
| Page suivante : Exemples concrets |
 En savoir plus
En savoir plus